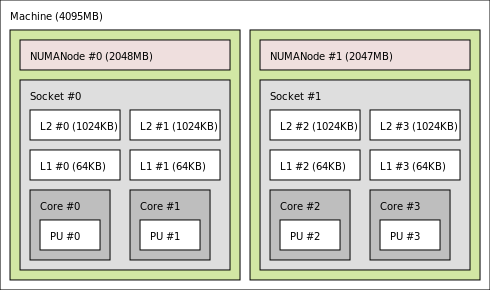
In this era of multiple CPUs per system this can be further complicated for programmers due to memory contention between each CPU. Also, virtualization introduces further complications. Consider the following diagram which shows the memory hierarchy currently in a 4 socket by 4 core system, which Ulrich Drepper mentions is going to be a common system in his excellent paper on computer memory.

Up until lately we've just had incremental improvements to the performance (not size), of RAM and mechanical hard disks, and CPU performance has diverged from them a lot. So changes to the memory hierarchy would both speed systems up a lot, and simplify software running on the CPU. It's these exciting changes that are happening now and in the next few years that I'm focusing on here.
[Update Oct 2015: As stated above, the divergence in speed between main memory and CPUs, implies much more performance for efficient use of the CPU caches. This is demonstrated in profiling hardware events, where adjusting the memory size and access pattern reduces the access depth in the memory hierarchy, thus greatly increasing performance. Now often it's not possible or practical to adjust all memory accesses, and so Intel as of the Broadwell micro-architecture (Sep 2014), has made CAT available (in certain XEON processors to start), which allows one to dynamically partition the shared cache, to limit what part of the cache can be written to by a core. In this way, restricting VMs/containers/apps/... to a core, will restrict them to evicting only part of the shared cache across cores, resulting in more efficient utilization of the system. This is well explained in Dan Luu's summary of CAT advantages. Partitioning functionality like this will also improve security isolation, and protect against side channel attacks. In future dynamic cache allocation will probably become available on most CPUs and across more cache levels.]
[Update Sep 2015: Note cache coherence is a big limitation to the number of cores possible, and a new "tardis" cache coherence model promising to remove the linear increase in cache accounting memory per core. It works by tagging the operations with a counter to order reads/writes, thus allowing cores to operate on older data if that suffices. Generation counters are useful for relative ordering rather than trying to synchronize with the universe with timestamps or something. I proposed on lkml (and still standby) a similar mechanism for relative ordering of files within a file system. Distributed cores/filesystems can use higher level methods for coherence, but within the "system" counters have an advantage.]
[Update Dec 2016: Intel is introducing 5-level paging to extend the address space available to newer processors from 64TiB to 4PiB.]
[Update Nov 2019: A tweat from Justin Cormack plotting the convergence of the memory hierarchy: ]

Solid State Disks
Consider for example how SSDs affect processing of a large file on a multi-core system. Because random seeks are of no extra cost on SSDs compared to mechanical disks, it's sensible for multiple cores to process separate portions of a file directly. With mechanical disks each core would just be fighting over the mechanical disk head, and slow down a lot compared to just a single core processing the file. In other words, data partitioning to take advantage of multiple cores is much more complicated for mechanical disks than for SSDs, requiring more complex logic and arrays of disks to achieve parallelization. Note for certain operations like sorting, one has to take RAM size into account, so the cores should process chunks of the file in parallel where each chunk is ((ram size/num cpus) - abit). For other operations like searching for example, RAM size is not a factor, and one can just split the file into chunks of (file size/num cpus). [Update Dec 2012: Given the widening disparity between traditional disks and SSDs, they're separating out to distinct layers in the memory hierarchy. To take advantage of this, hybrid drives are becoming available, as is software to transparently combine separate drives, like SRT or Linux solutions like bcache.] [Update Jan 2016: ACM Queue discussion on faster non volatile storage "it is rare that the performance assumptions that we make about an underlying hardware component change by 1,000x".]2 Transistor DRAM
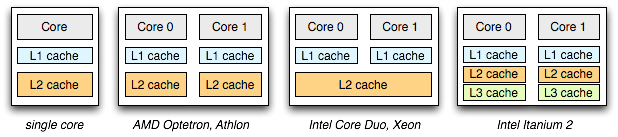
2T DRAM currently being developed by Intel, has the potential to enhance caches in CPUs at least. You can see in the diagram above that the level 2 cache can be both used to speed access to the relatively slow RAM and speed up communication between cores in a single processor. When this memory wall is lowered it again gives the opportunity to use different algorithms, especially on multi core systems. Tian Tian of Intel has written a good article on how shared caches enhance a multi-core system and how programmers can take further advantage of them. There also is another good ACM article on optimizing application performance in the presence of caches, and this excellent presentation on lock free algorithms taking considerations of the current memory hierarchy. [Update Dec 2008: I noticed an IEEE reference to a Sandia National Laboratories simulation, which showed that for many applications, the memory wall with current architectures causes performance to decline with greater than 8 processors, so it looks like technology like 2T DRAM will be required in the near future.]MRAM and Memristors
These technologies have the potential to be the biggest game changers. They're essentially very fast non volatile memory, and so will affect both current RAM and flash technologies.MRAM has been in development for a while, but while being about as twice as fast as current RAM technologies, it's much more expensive. However researchers in Germany have recently figured out how to make it 10 times faster again!
Memristors have recently been created by HP labs and again they have the potential to be a fast, dense, cheap, non volatile memory. The memristor was first theorized in 1971 by Leon Chua, being a fourth fundamental circuit element, having properties that cannot be achieved by any combination of the other three elements (resistor, inductor, capacitor). [Update Sep 2010: Memristors will be available by 2014 apparently.] [Update Nov 2011: You can apparently make home-made memristors :)] [Update Jun 2014: Informative memristor info and roadmap from HP] Interesting times...
[Update Jul 2015: 3D Xpoint was announced by Intel/Micron to be available in 2016. Mostly marketing for now, but as a transistor-less non-volatile technology, has potential to be another level in the hierarchy under DRAM at first, and eventually replacing it altogether.]
[Update Mar 2017: 3D Xpoint is available first as a 375GB SSD on a PCIe card (for $1500), with U.2 available in the second half of 2017 at up to 1.5TB. The throughput is currently about the same as NAND flash, but the latency is much better, being about 100 times faster (and DRAM being about 10 times faster again). Other advantages over traditional flash is that it's byte addressable and about 5 times more write cycles are supported. DIMMs will be available in 2018 for more natural byte addressing applications, but this is currently middleware available that transparently merges PCIe and DRAM storage into byte addressable memory].